Using Fast Weights to Attend to the Recent Past
论文相关信息
相关知识
记忆分类
- 瞬时记忆,又称为感觉记忆或者感觉登记——也就是你现在看到、听到感觉到的一切信息在人脑中的反应。
- 短时记忆——请你现在回忆看这个答案前你再看什么?这就是短时记忆,一般持续15~30秒。(没有复述的情况下)
- 长时记忆——也就是一分钟以上的记忆,最长可以达到终身。
以上定义来自于《普通心理学》北京师范出版社·彭聃龄
循环神经网络
长短时记忆网络
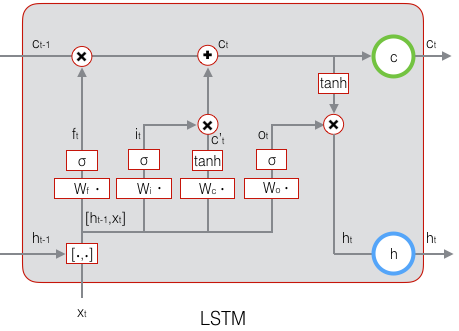
论文理解
普通的循环神经网络有两种记忆类型,即短期记忆和长期记忆。隐藏层的神经元负责保持短期记忆,每次迭代都更新,记忆容量为$O(H)$,其中$H$是隐藏层神经元的个数。权重向量保持着长期记忆,记忆容量为$O(H ^{2})+O(IH)+O(HO)$,其中$I$和$O$是输入和输出单元的个数。LSTM增加了各种门和状态信息,使得记忆可以保存的更久,但是它的短期记忆容量依旧为$O(H)$。从生理学上来说,人的记忆并不是存储在神经元中。生理学上表明,大脑的短期记忆的某一种实现方式是:通过突出末梢的$[Ca ^{2+}]]$去极化建立短期记忆,而又通过递质的损耗来遗忘。这也就是说大脑的短期记忆并不是存储于神经元中的,而是存储在突触的变化中。这样短期记忆的容量就可以达到$O(H ^{2})$。
快速联想记忆
1970-1980年的主流思想是,记忆不是以简单的拷贝神经活动的模式存储的,而是在需要时从存有信息的权重中重建的。$O(N ^{2})$个权重至多存储$O(N)$个实值向量,每个向量有$O(N)$个分量。至于实际存储容量能够达到什么程度则取决于我们采用的存储规则。由于我们觉得一个简单的,无迭代的存规则比最大化容量要重要一些,所以我们采用外积规则来存储隐藏快速衰减的神经向量。
快速联想记忆的优势:
- 对于像神经图灵机,神经堆栈,记忆网络这些模型暂时没有生理学的依据,但是大脑实现快速联想记忆却是有依据的即通过突触的变化。
- 在快速联想记忆中,我们不必决定什么时候读记忆什么时候写记忆,快速联想记忆时时刻刻都在更新。每当输入变化时,都可以通过模型反应到隐藏状态中去。
模型
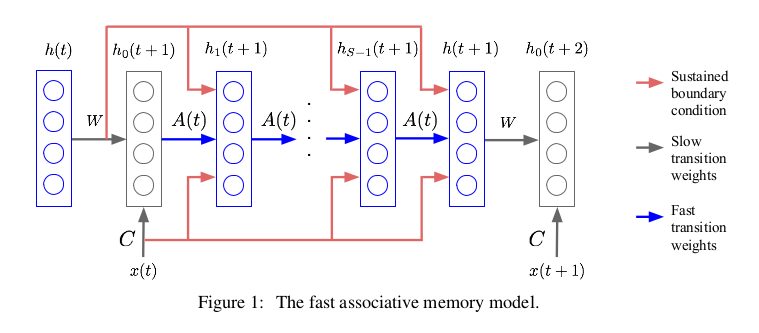
迭代公式 \(A \left ( t \right ) = \lambda A \left ( t-1 \right ) + \eta h \left ( t \right ) h \left ( t \right ) ^{T}\)
\[(Assuming\ A\ is\ 0\ at\ the\ beginning\ of\ the\ sequence)\] \[\Longrightarrow A \left ( t \right ) = \eta \sum _{\tau = 1} ^{\tau = t} \lambda ^{t- \tau} h \left ( \tau \right ) h \left ( \tau \right ) ^{T}\] \[h _{0} \left ( t+1 \right ) = f \left ( Wh \left ( t \right ) + Cx \left ( t \right ) \right )\] \[h _{S} \left ( t+1 \right ) = f \left ( \left [ Wh \left ( t \right ) + Cx \left ( t \right ) \right ] + A \left ( t \right ) h _{S-1} \left ( t+1 \right ) \right )\] \[h \left ( t+1 \right ) = h _{S} \left ( t+1 \right )\] \[A \left ( t \right ) h _{s-1} \left ( t+1 \right ) = \eta \sum _{\tau = 1} ^{\tau = t} \lambda ^{t- \tau} h \left ( \tau \right ) \left [ h \left ( \tau \right ) ^{T} h _{s-1} \left ( t+1 \right ) \right ]\]其中$A \left ( t \right )$不需要训练,是随着时间和输入更新的 Layer normalized fast weight 快速联想记忆网络的一个可能潜在的问题是两个隐藏向量的标量积可能会消失或者爆炸,而最近提出的layer normalization在处理这样的问题时表现出色,并且可以减少训练时间,所以我们在快速联想记忆网络中使用这一技术如下: \(h _{S} \left ( t+1 \right ) = f \left (LN \left [ Wh \left ( t \right ) + Cx \left ( t \right ) + A \left ( t \right ) h _{S-1} \left ( t+1 \right ) \right ] \right )\) 其中$LN\left [\cdot \right ] $代表layer normalization。
实验结果
-
联想检索

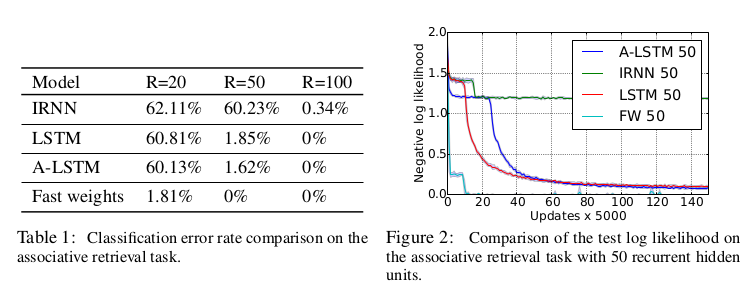
-
在视觉注意力模型中综合瞥见
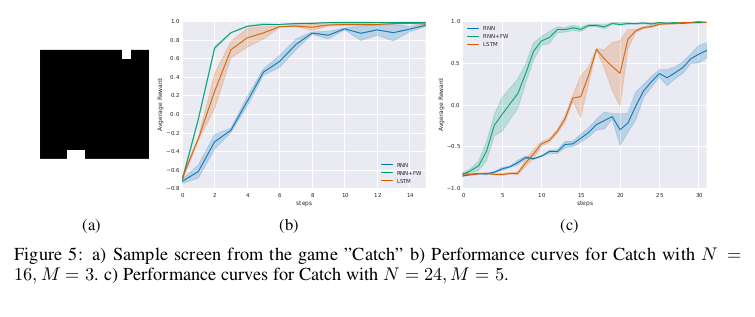
视觉注意力模型能将注意力集中在图像的某些重要的部分,而忽略图像的混乱的背景,该模型不仅决定它下一步要看什么,而且要把所看的东西都记住以便进行正确的图像分类。视觉注意力模型能在大量图像输入中找出多个图像并进行正确分类。但是它的瞥见策略过于简单,只能使用单一尺度的瞥见,并且扫描图像的方式也过于死板。相对来说人眼的运动就复杂多了,人眼可以看同一东西的不同尺度,并且能够将看到的东西给予不同的重要程度划分。但是这要求我们能具有短期的记忆能记住我们在刚开始的一系列瞥见中发现了什么。 典型的视觉注意力模型,比较复杂且效果的方差比较大,为了证明快速联想记忆对视觉注意力模型有助益,我们让提前定义好了视觉注意力模型的控制信号,所以模型不需要学习下一步要看什么,这样可以更加明显的看出快速权重的作用。
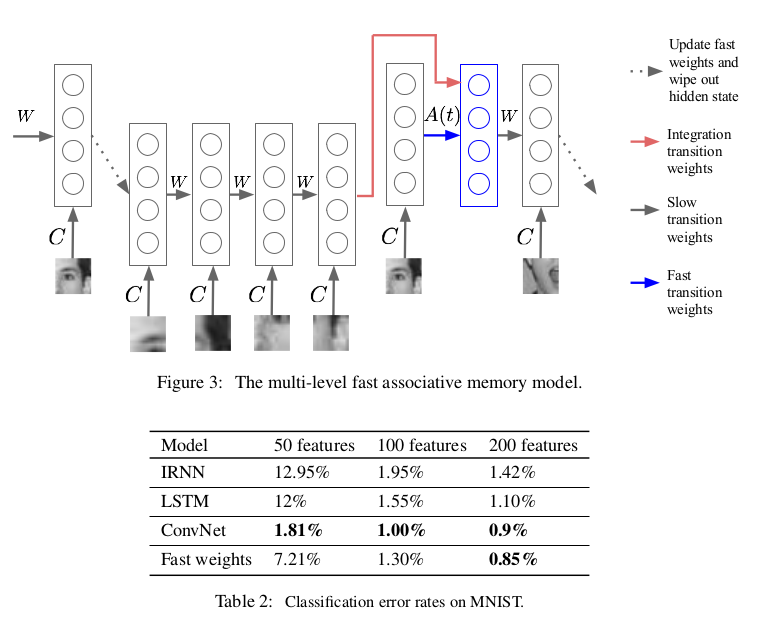
- 面部表情识别

- 具有记忆的智能体
扩展阅读
-
A-LSTM
-
visual attention models(模型)
-
Negative log likelihood(评价指标)
-
batch normalization(归一化)
-
layer normalization(归一化)
-
Asynchronous advantage actor-critic method(训练方法)
作者信息
Jimmy Ba:University of Toronto
-
Using Fast Weights to Attend to the Recent Past (2016)
-
Learning Wake-Sleep Recurrent Attention Models (2015)
-
Do Deep Nets Really Need to be Deep? (2014)
-
Adaptive dropout for training deep neural networks (2013)
Geoffrey Hinton:University of Toronto and Google Brain
计算机学家和心理学家,反向传播算法和对比散度算法的发明人之一,深度学习的积极推动者。盖茨比计算神经科学中心的创始人,多伦多大学计算机系教授。对神经网络的研究的其它贡献包括Boltzmann机器,分布式表征,时滞神经网络,混合专家、变分学习,专家产品和深信网络。研究兴趣是用丰富传感器输入的非监督式多层神经网络学习程序。可以说是Deep Learning学派的开山祖师爷。
-
Attend, Infer, Repeat: Fast Scene Understanding with Generative Models (2016)
-
A Better Way to Pretrain Deep Boltzmann Machines (2012)
-
ImageNet Classification with Deep Convolutional Neural Networks (2012)
-
Gated Softmax Classification (2010)
-
Generating more realistic images using gated MRF’s (2010)
-
Learning to combine foveal glimpses with a third-order Boltzmann machine (2010)
-
Phone Recognition with the Mean-Covariance Restricted Boltzmann Machine (2010)
Volodymyr Mnih:Google DeepMind
-
Learning values across many orders of magnitude (2016)
-
Strategic Attentive Writer for Learning Macro-Actions (2016)
-
Recurrent Models of Visual Attention (2014)
-
Generating more realistic images using gated MRF’s (2010)
Joel Leibo:Google DeepMind
-
Learning invariant representations and applications to face verification (2013)
-
Why The Brain Separates Face Recognition From Object Recognition (2011)
Catalin Ionescu:Google DeepMind